How to extract content from PDF documents in C# and VB.NET
In today's digital world, PDF documents are essential for storing and sharing information. Whether you're dealing with reports, manuals, invoices, or any other document type, extracting content from these PDFs is often necessary for further processing or analysis.
This article will explore how to perform this task effortlessly using the GemBox.Pdf library. Aimed at C# and VB.NET developers, this guide will walk you through the steps of reading text content from a PDF document, making it easier to integrate this functionality into your applications.
Table of contents:
- Install and configure the GemBox.Pdf library
- Reading Content Within the Given Bounds
- Reading Content with Structural Integrity
- Reading Content by Paragraphs
Install and configure the GemBox.Pdf library
Before you start, you need to install GemBox.Pdf. The best way to do that is to install the NuGet Package by following these instructions:
Add the GemBox.Pdf library as a package using the following command from the NuGet Package Manager Console:
Install-Package GemBox.PdfAfter installing the GemBox.Pdf library, you must call the
ComponentInfo.SetLicensemethod before using any other member of the library.ComponentInfo.SetLicense("FREE-LIMITED-KEY");
In this tutorial, by using "FREE-LIMITED-KEY", you will be using GemBox's free mode. This mode allows you to use the library without purchasing a license, but with some limitations. If you purchased a license, you can replace "FREE-LIMITED-KEY" with your serial key.
You can check this page for a complete step-by-step guide to installing and setting up GemBox.Pdf in other ways.
Reading Content Within the Given Bounds
GemBox.Pdf supports exporting text with the given parameters. One of the use cases is to extract text within the given bounds. This functionality is particularly useful for extracting specific sections of a document, such as tables, paragraphs, or other elements contained within certain coordinates.
using (var document = PdfDocument.Load("%#Invoice.pdf%"))
{
// Get the page from which we want to make the extraction
var page = document.Pages[0];
// Extract text content from the given bounds
var text = page.Content.GetText(new PdfTextOptions
{
Bounds = new PdfQuad(140, 640, 250, 660),
Order = PdfTextOrder.Reading
}).ToString();
// Writing the extracted text
Console.WriteLine($"Result: {text}");
if (DateTime.TryParse(text, out var dateTime))
{
var dateDifference = DateTime.UtcNow - dateTime;
Console.Write($"Created {dateDifference.Days} days {dateDifference.Hours} hours {dateDifference.Minutes} minutes ago.");
}
}' If using the Professional version, put your serial key below.
ComponentInfo.SetLicense("FREE-LIMITED-KEY")
Dim dateTime As Date = Nothing
Using document = PdfDocument.Load("%#Invoice.pdf%")
' Get the page from which we want to make the extraction
Dim page = document.Pages(0)
' Extract text content from the given bounds
Dim text = page.Content.GetText(New PdfTextOptions With {
.Bounds = New PdfQuad(140, 640, 250, 660),
.Order = PdfTextOrder.Reading
}).ToString()
' Writing the extracted text
Console.WriteLine($"Result: {text}")
If Date.TryParse(text, dateTime) Then
Dim dateDifference = Date.UtcNow - dateTime
Console.Write($"Created {dateDifference.Days} days {dateDifference.Hours} hours {dateDifference.Minutes} minutes ago.")
End If
End Using
Extracting Tables
You can easily extract tables by defining the coordinates of a table within a PDF. The code below demonstrates how to do that by iterating through all table rows and columns and returning an enumeration of PdfText instances representing the table cell text content. This way, you can extract the entire table content for further analysis or manipulation.
public static IEnumerable<IEnumerable<PdfText>> GetTableRows(PdfPage page, PdfPoint topLeft, IList<double> columnWidths, double rowHeight, int rowCount)
{
var currentY = topLeft.Y;
for (var i = 0; i < rowCount; i++)
{
yield return GetRowCells(page, columnWidths, topLeft.X, currentY, currentY - rowHeight);
currentY -= rowHeight;
}
}
public static IEnumerable<PdfText> GetRowCells(PdfPage page, IList<double> columnWidths, double startX, double bottom, double top)
{
var currentX = startX;
foreach (var columnWidth in columnWidths)
{
yield return page.Content.GetText(new PdfTextOptions
{
Bounds = new PdfQuad(currentX, bottom, currentX + columnWidth, top)
});
currentX += columnWidth;
}
}Public Shared Iterator Function GetTableRows(ByVal page As PdfPage, ByVal topLeft As PdfPoint, ByVal columnWidths As IList(Of Double), ByVal rowHeight As Double, ByVal rowCount As Integer) As IEnumerable(Of IEnumerable(Of PdfText))
Dim currentY = topLeft.Y
For i = 0 To rowCount - 1
Yield GetRowCells(page, columnWidths, topLeft.X, currentY, currentY - rowHeight)
currentY -= rowHeight
Next
End Function
Public Shared Iterator Function GetRowCells(ByVal page As PdfPage, ByVal columnWidths As IList(Of Double), ByVal startX As Double, ByVal bottom As Double, ByVal top As Double) As IEnumerable(Of PdfText)
Dim currentX = startX
For Each columnWidth In columnWidths
Yield page.Content.GetText(New PdfTextOptions With {
.Bounds = New PdfQuad(currentX, bottom, currentX + columnWidth, top)
})
currentX += columnWidth
Next
End Function
Automated Data Extraction
For cases where content might not be at the exact position in every document, you can use the following class to extract data by providing its text content as a string. This is especially important when processing a large number of documents automatically.
public class DataExtractor
{
private readonly PdfPage page;
private readonly PdfText text;
public DataExtractor(PdfPage page)
{
this.page = page;
this.text = page.Content.GetText();
}
public string ExtractText(string labelText)
{
var foundText = this.text.Find(labelText).First();
var bounds = foundText.Bounds;
var quads = new PdfQuad(bounds.Right, bounds.Bottom, double.MaxValue, bounds.Top);
var value = this.page.Content.GetText(new PdfTextOptions { Bounds = quads });
return value.ToString();
}
}Public Class DataExtractor
Private ReadOnly page As PdfPage
Private ReadOnly text As PdfText
Public Sub New(page As PdfPage)
Me.page = page
Me.text = page.Content.GetText()
End Sub
Public Function ExtractText(labelText As String) As String
Dim foundText = Me.text.Find(labelText).First()
Dim bounds = foundText.Bounds
Dim quads = New PdfQuad(bounds.Right, bounds.Bottom, Double.MaxValue, bounds.Top)
Dim value = Me.page.Content.GetText(New PdfTextOptions With {
.bounds = quads
})
Return value.ToString()
End Function
End Class
In summary, the PdfContentGroup.GetText method simplifies the process of content extraction within defined bounds, opening up numerous possibilities for customization and automation in handling PDF documents. Whether you're building applications for data processing, content management, or accessibility, this method offers a robust solution to meet your needs.
For detailed information on all possible options on using the PdfContentGroup.GetText method, check the PdfTextOptions documentation page.
Reading Content with Structural Integrity
The PdfContentGroup.GetText method provides an efficient way to read content from a PDF file while preserving the structure as closely as possible to the original document. This enables users to extract data from a PDF without losing formatting, alignments, and other structural elements.
The code below shows how to read content with structural integrity by setting the PdfTextOptions.Whitespaces to include the NewLine option along with the Space and Blank options.
// Load the PDF file to extract content
using (var document = PdfDocument.Load("%#Structural.pdf%"))
{
// Get the page from which we want to make the extraction
var page = document.Pages[0];
// Extract text content from the page, keeping the structural integrity
var text = page.Content.GetText(new PdfTextOptions
{
FontFace = new PdfFontFace("Consolas"),
Order = PdfTextOrder.Reading,
Whitespaces = PdfTextWhitespaces.Space | PdfTextWhitespaces.Blank | PdfTextWhitespaces.NewLine
}).ToString();
// Writing the extracted text
Console.WriteLine(text);
}' If using the Professional version, put your serial key below.
ComponentInfo.SetLicense("FREE-LIMITED-KEY")
' Load the PDF file to extract content
Using document = PdfDocument.Load("%#Structural.pdf%")
' Get the page from which we want to make the extraction
Dim page = document.Pages(0)
' Extract text content from the page, keeping the structural integrity
Dim text = page.Content.GetText(New PdfTextOptions With {
.FontFace = New PdfFontFace("Consolas"),
.Order = PdfTextOrder.Reading,
.Whitespaces = PdfTextWhitespaces.Space Or PdfTextWhitespaces.Blank Or PdfTextWhitespaces.NewLine
}).ToString()
' Writing the extracted text
Console.WriteLine(text)
End Using
The PdfContentGroup.GetText method's ability to read content while maintaining structural integrity has several significant applications.
Document Conversion
Converting PDF documents to other text-based formats (such as TXT or DOCX) without losing the original layout and formatting becomes seamless with the following method.
public static string Textify(PdfPage page)
{
var text = page.Content.GetText(new PdfTextOptions
{
FontFace = new PdfFontFace("Arial"),
Order = PdfTextOrder.Reading,
Whitespaces = PdfTextWhitespaces.Blank | PdfTextWhitespaces.NewLine
});
return text.ToString();
}Public Function Textify(ByVal page As PdfPage) As String
Dim text = page.Content.GetText(New PdfTextOptions With {
.FontFace = New PdfFontFace("Arial"),
.Order = PdfTextOrder.Reading,
.Whitespaces = PdfTextWhitespaces.Blank Or PdfTextWhitespaces.NewLine
})
Return text.ToString()
End FunctionData Migration
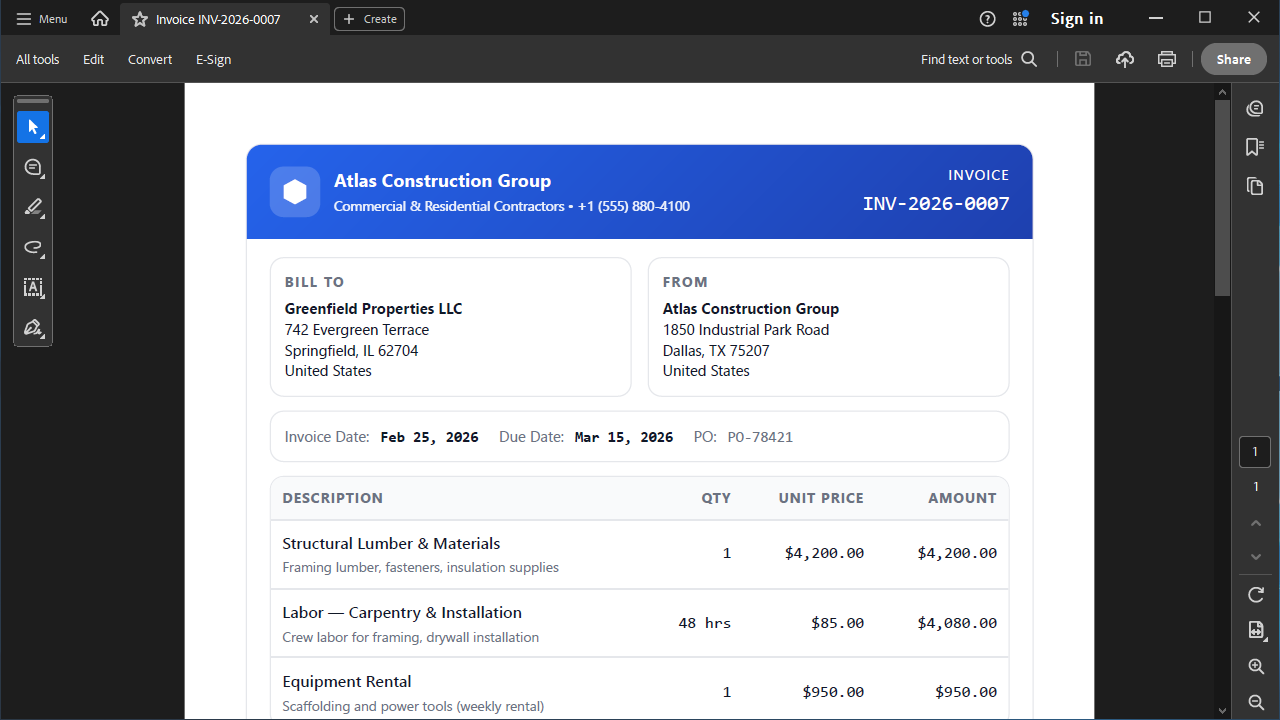
When migrating data from PDF to CSV, you can use the following code to preserve the structural integrity which ensures that the content remains consistent and accurate.
public static string ToCsv(PdfPage page)
{
var text = page.Content.GetText(new PdfTextOptions
{
Bounds = new PdfQuad(28, 622, 567, 396),
Order = PdfTextOrder.Content,
Whitespaces = PdfTextWhitespaces.Blank | PdfTextWhitespaces.NewLine
}).ToString();
// Replacing large gaps in text with a separator
var csv = Regex.Replace(text, @"\s{4,}", ",");
return csv;
}Public Function ToCsv(ByVal page As PdfPage) As String
Dim text = page.Content.GetText(New PdfTextOptions With {
.Bounds = New PdfQuad(28, 622, 567, 396),
.Order = PdfTextOrder.Content,
.Whitespaces = PdfTextWhitespaces.Blank Or PdfTextWhitespaces.NewLine
}).ToString()
' Replacing large gaps in text with a separator
Dim csv = Regex.Replace(text, "\s{4,}", ",")
Return csv
End Function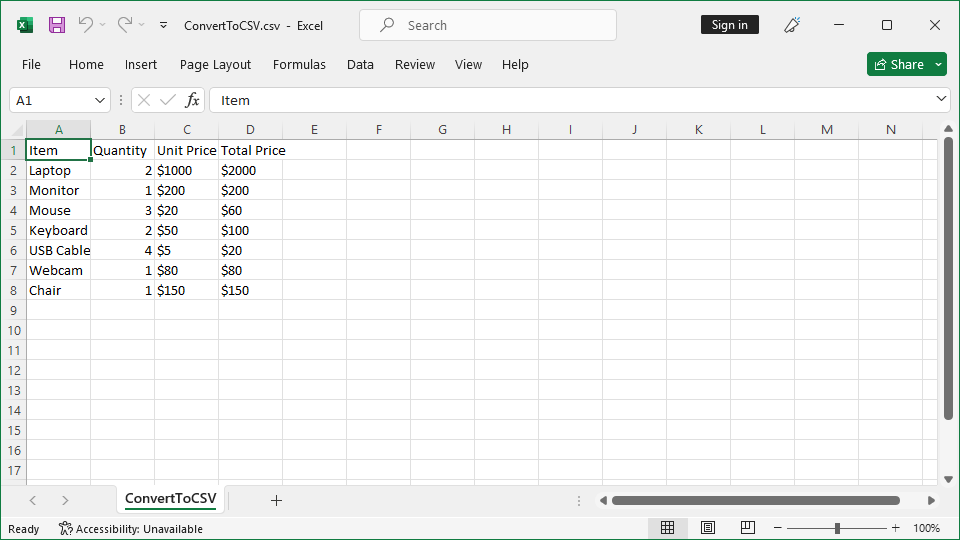

Reading Content by Paragraphs
The PdfContentGroup.GetText method can be used to read content from a PDF file as paragraphs by converting content of the same paragraph into one line. This approach ensures better results when copying and pasting the content into text editors like MS Word, as it preserves the paragraph structure.
// If using the Professional version, put your serial key below.
ComponentInfo.SetLicense("FREE-LIMITED-KEY");
using (var document = PdfDocument.Load("%#Chapters.pdf%"))
{
// Get the page that we want to make extraction
var page = document.Pages[0];
// Get the content of the page
var content = page.Content;
// Extract text content from the given bounds, keeping the structural integrity
var text = content.GetText(new PdfTextOptions
{
Order = PdfTextOrder.Content,
Bounds = new PdfQuad(0, 100, 600, 640),
Whitespaces = PdfTextWhitespaces.Space | PdfTextWhitespaces.NewLine
});
var linesRegex = new Regex(@"^.*$", RegexOptions.Multiline);
// Writing extracted paragraphs starting with a tab character and adding an empty line between them
foreach (var line in text.Find(linesRegex))
Console.WriteLine($"\t{line}{Environment.NewLine}");
}' If using the Professional version, put your serial key below.
ComponentInfo.SetLicense("FREE-LIMITED-KEY")
Using document = PdfDocument.Load("%#Chapters.pdf%")
' Get the page from which we want to make extraction
Dim page = document.Pages(0)
' Extract text content from the given bounds, keeping the structural integrity
Dim text = page.Content.GetText(New PdfTextOptions With {
.Order = PdfTextOrder.Content,
.Bounds = New PdfQuad(0, 100, 600, 640),
.Whitespaces = PdfTextWhitespaces.Space Or PdfTextWhitespaces.NewLine
})
Dim linesRegex = New Regex("^.*$", RegexOptions.Multiline)
' Writing extracted paragraphs starting with a tab character and adding an empty line between them
For Each line In text.Find(linesRegex)
Console.WriteLine($"{Microsoft.VisualBasic.ControlChars.Tab}{line}{Environment.NewLine}")
Next
End Using
The ability to convert texts in the same paragraph into one line has various practical applications.
Content Migration
The method below can be used for transferring content to word processors like MS Word, maintaining paragraph integrity, which ensures a smoother transition and preserves the readability of the text. Note that this code requires the GemBox.Document library for loading DOCX files.
// If using the Professional version, put your serial key below.
GemBox.Pdf.ComponentInfo.SetLicense("FREE-LIMITED-KEY");
GemBox.Document.ComponentInfo.SetLicense("FREE-LIMITED-KEY");
using (var pdfDocument = PdfDocument.Load("%#Chapters.pdf%"))
{
var document = new DocumentModel();
// Get the page that we want to make extraction
var page = pdfDocument.Pages[0];
var section = new Section(document);
document.Sections.Add(section);
var text = page.Content.GetText(new PdfTextOptions
{
Order = PdfTextOrder.Content,
Bounds = new PdfQuad(0, 100, 600, 640),
Whitespaces = PdfTextWhitespaces.Space | PdfTextWhitespaces.NewLine
});
var paragraphs = text.ToString()
.Split(new[] { Environment.NewLine }, StringSplitOptions.RemoveEmptyEntries)
.Select(i => new Paragraph(document, i));
foreach (var paragraph in paragraphs)
section.Blocks.Add(paragraph);
document.Save("Chapters.docx");
}' If using the Professional version, put your serial key below.
GemBox.Pdf.ComponentInfo.SetLicense("FREE-LIMITED-KEY")
GemBox.Document.ComponentInfo.SetLicense("FREE-LIMITED-KEY")
Using pdfDocument = GemBox.Pdf.PdfDocument.Load("%#Chapters.pdf%")
Dim document = New DocumentModel()
' Get the page that we want to make extraction
Dim page = pdfDocument.Pages(0)
Dim section = New Section(document)
document.Sections.Add(section)
Dim text = page.Content.GetText(New PdfTextOptions With {
.Order = PdfTextOrder.Content,
.Bounds = New PdfQuad(0, 100, 600, 640),
.Whitespaces = PdfTextWhitespaces.Space Or PdfTextWhitespaces.NewLine
})
Dim paragraphs = text.ToString().Split({Environment.NewLine}, StringSplitOptions.RemoveEmptyEntries).[Select](Function(i) New Paragraph(document, i))
For Each paragraph In paragraphs
section.Blocks.Add(paragraph)
Next
document.Save("Chapters.docx")
End Using
Data Analysis
Analyzing textual content is facilitated when paragraphs are maintained as single lines, especially when performing natural language processing or text mining.
public static async Task<string> Translate(PdfPage page)
{
var text = page.Content.GetText(new PdfTextOptions
{
Bounds = new PdfQuad(0, 100, 600, 700),
Order = PdfTextOrder.Content,
Whitespaces = PdfTextWhitespaces.Space | PdfTextWhitespaces.NewLine
}).ToString();
var translator = new GTranslate.Translators.GoogleTranslator();
var result = await translator.TranslateAsync(text, "en");
return result.Translation;
}Public Shared Async Function Translate(ByVal page As PdfPage) As Task(Of String)
Dim text = page.Content.GetText(New PdfTextOptions With {
.Bounds = New PdfQuad(0, 100, 600, 700),
.Order = PdfTextOrder.Content,
.Whitespaces = PdfTextWhitespaces.Space Or PdfTextWhitespaces.NewLine
}).ToString()
Dim translator = New GTranslate.Translators.GoogleTranslator()
Dim result = Await translator.TranslateAsync(text, "en")
Return result.Translation
End FunctionAccessibility
Enhancing readability for assistive technologies by maintaining paragraph integrity allows for a more user-friendly experience for individuals with visual impairments or other accessibility needs. The example below demonstrates such case, using the SpeechSynthesizer class.
public static void Listen(PdfPage page)
{
var text = page.Content.GetText(new PdfTextOptions
{
Order = PdfTextOrder.Content,
Whitespaces = PdfTextWhitespaces.Space | PdfTextWhitespaces.NewLine
}).ToString();
var synth = new System.Speech.Synthesis.SpeechSynthesizer();
synth.SetOutputToDefaultAudioDevice();
synth.Speak(text);
}Public Shared Sub Listen(ByVal page As PdfPage)
Dim text = page.Content.GetText(New PdfTextOptions With {
.Order = PdfTextOrder.Content,
.Whitespaces = PdfTextWhitespaces.Space Or PdfTextWhitespaces.NewLine
}).ToString()
Dim synth = New Speech.Synthesis.SpeechSynthesizer()
synth.SetOutputToDefaultAudioDevice()
synth.Speak(text)
End SubConclusion
Now you know how to use GemBox.Pdf to export text from your PDF files programmatically. Besides the use cases described in this article, you can use the GemBox.Pdf API to read, write, merge, and split PDF files and execute other low-level object manipulations in a very straightforward and quick way.
For more information regarding the GemBox.Pdf library, check the documentation pages.